
Case: Aldipress
Aldipress is al meer dan 50 jaar marktleider in distributie en marketing van tijdschriften, strips, romans en puzzels in Nederland.
Als partner voor uitgevers en retailers is de core business van Aldipress het vinden van effectieve oplossingen voor assortimentsbeheer, oplagebeheer, schappresentaties en promoties. Het werd in 2019 overgenomen door DPG en bedient momenteel: 120 uitgevers, 1.100 tijdschriften en 5.200 verkooppunten (supermarkten, boekhandels, benzinestations, ziekenhuizen).
Dit is een Level 2 afstudeercase het JADS Professioneel Onderwijs programma.

De uitdaging
Sinds de komst van online media is de verkoop van gedrukte tijdschriften flink afgenomen. Digitalisering schept veel nieuwe kansen voor uitgevers, maar leidt uiteraard tot dalende inkomsten uit gedrukte tijdschriften. Bovendien is schapruimte in een supermarkt erg duur. Deze trends hebben Aldipress en supermarktmanagers uitgedaagd om toch winst te kunnen maken in een krimpende markt. In essentie komt dit neer op een optimale afstemming van vraag en aanbod van de vele tijdschriften over vele verschillende soorten winkels.
Traditioneel was de strategie van Aldipress om zoveel mogelijk tijdschriften te verkopen, van zoveel mogelijk uitgevers, via zoveel mogelijk verkooppunten. In navolging van een nieuwe bedrijfsstrategie in 2020 werd de aanpak voor de distributie van gedrukte tijdschriften gewijzigd om te focussen op een kernassortiment per winkeltype. Je kunt je voorstellen dat dit een behoorlijke mindshift was voor een bedrijf dat al tientallen jaren zeer succesvol is met een “vast” bedrijfsconcept.
De resultaten
Om deze nieuwe strategie te ondersteunen met data-analyse, stapte Harm Bodewes in en paste ‘unsupervised machine learning’ toe om verschillende verschillende winkeltypes te identificeren in een zee aan numerieke data. In het bijzonder gebruikte hij K-Means clustering die verschillende numerieke attributen als invoer nodig heeft om een vooraf gedefinieerd aantal (K) clusters te identificeren. De resultaten van de verschillende runs van het clusteringalgoritme werden kwalitatief geanalyseerd om tot een praktische set winkeltypes te komen. Daarnaast is per winkeltype een kernassortiment en een uniforme schapindeling gedefinieerd. De oplossing is ontwikkeld in april-september 2021 en wordt momenteel (2022) geïmplementeerd bij SUPERUNIE en andere supermarkten in Nederland.
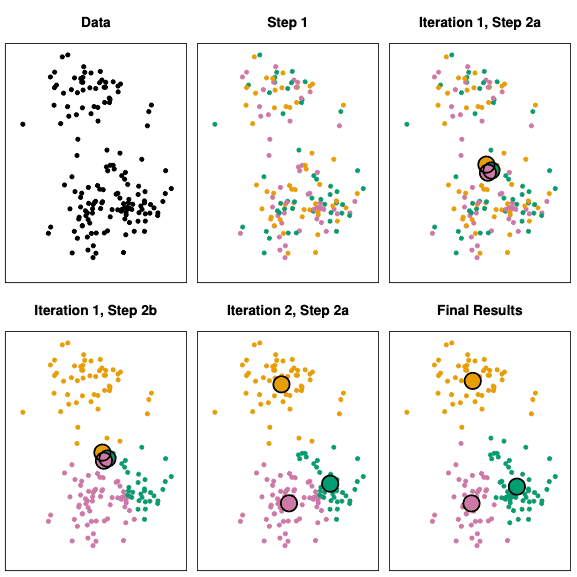
De uitkomst
De figuur hiernaast illustreert hoe deze clusters worden bepaald. Het algoritme werkt in verschillende iteraties en elke iteratie heeft verschillende stappen. Het doel van het algoritme is om aan elke waarneming een kleur toe te kennen. In dit voorbeeld zien we drie verschillende kleuren, dus k=3. Het bovenstaande voorbeeld bevindt zich in de 2-dimensionale ruimte, je kunt een x- en een y-as zien. De kracht van het algoritme is dat je het ook in de n-dimensionale ruimte kunt uitvoeren, wat natuurlijk moeilijker te visualiseren is. In het geval van Aldipress hebben we een 40-dimensionale ruimte gebruikt.
We hebben dit algoritme geïmplementeerd in een Python-notebook. De invoergegevens kwamen van zowel SAS (de forecasting “engine” van Aldipress) als SAP (het ERP-systeem dat alle masterdata van Aldipress bevat). Hiernaast vind je de output voor SUPERUNIE winkels met 3 meter schapruimte.
Op basis van de output definieerde Aldipress 3 winkeltypes: BUDGET, FAMILY en PREMIUM. In BUDGET-winkels gaat Aldipress meer TV Guides (wie koopt er in 2022 trouwens nog tv-magazines?) en Gossip. In PREMIUM zal Aldipress meer Glossies en Woman-magazines leveren. De categorie FAMILIE is “voor ieder wat wils”.
De clusteranalyse bevat zeer relevante informatie voor Aldipress, aangezien deze oplossing de retourkosten en het risico van out-of-stock kan minimaliseren door een goede inschatting te maken van het aantal te verkopen tijdschriften. Ook de supermarktmanager is blij met deze oplossing, aangezien hij alleen tijdschriften gaat verkopen die de consument echt wil. De kleine uitgevers met zeer specifieke tijdschriften zijn misschien minder gelukkig en zullen op zoek gaan naar andere manieren van distributie.

Quote Harm Bodewes

Quote Harm Bodewes
“Dit project was het ultieme eindresultaat van mijn JADS-opleiding. Het project bevatte verschillende elementen die echt waardevol waren voor mijn professionele ontwikkeling:
- De sponsor (Aldipress) stimuleerde me (op een vriendelijke manier…) om de beste resultaten te behalen. Dat vond ik leuk, op deze manier kon ik echt impact maken met deze opdracht.
- Na het uitvoeren van enkele groepsopdrachten in het JADS-curriculum, was deze opdracht de eerste waarin ik alle fasen van CRISP-DM alleen deed. Dit was een geweldige leerervaring.
- De coaching door JADS was van een uitstekend niveau. Het initiatief moet van de student komen, maar ik denk dat dit van studenten in deze fase van het curriculum verwacht mag worden.
Over het algemeen ben ik erg blij met deze opdracht, het was de kers op de taart van mijn JADS-opleiding.”

Waarom samenwerken met JADS
JADS biedt innovatieve datawetenschapsprogramma’s op undergraduate, graduate en postdoctorale niveau, voert baanbrekend datawetenschappelijk onderzoek uit en biedt geweldige zakelijke kansen met een voortdurend groeiend ecosysteem. Van startups tot KMO’s en grote ondernemingen, onze zakenpartners krijgen toegang tot talent, kennis op hoog niveau en zakelijke kansen.
Werk samen met JADS zoals 300+ andere organisaties en bedrijven en geef vorm aan jouw datagedreven toekomst.